
5 月 6 日,蚂蚁金服副 CTO 胡喜在 2019 年 QCon 上做了《蚂蚁金服十五年技术架构演进之路》的演讲。借此机会,也和大家深入讨论了一下蚂蚁金服对金融科技未来的判断,并首次对外曝光了蚂蚁金服技术人才培训体系以及 BASIC College 项目。

主要观点
- 蚂蚁金服过去十五年,通过技术重塑了支付和微贷业务。Blockchain (区块链)、ArtificialIntelligence(人工智能)、Security(安全)、 IoT(物联网)和 Cloud computing(云计算),这五大 BASIC 技术仍会是金融科技的基石。BASIC 里最基础的能力是计算能力,只有不断提升计算能力,才能适应未来应用场景的千变万化。
- 金融交易技术的核心是金融分布式中间件,关键是分布式数据库的能力。对数据不丢失,业务不停机是金融级高可用的极致追求,同时,更要具备主动发现风险和自我恢复的能力。
- 金融级分布式系统,最终将走向云原生化。现有的中间件能力将通过 service mesh 形式下沉至基础设施。安全可信的执行环境是金融级系统的底线,安全容器将成为金融行业的强需求。
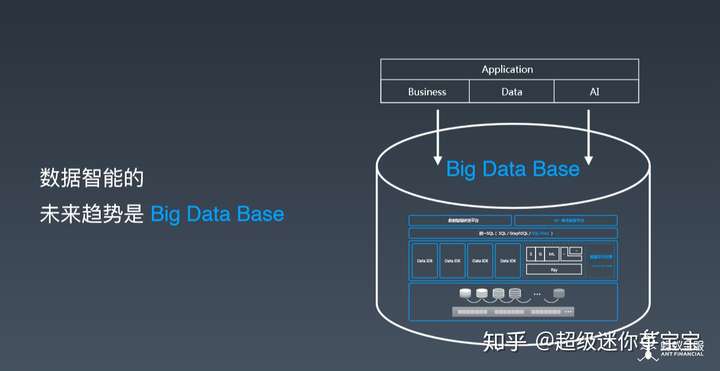
- 金融级数据智能未来的趋势是 Big Data Base,我们需要开放式的计算架构,从统一存储规范,可插拔的引擎组件,融合计算引擎,到统一的智能 SQL,数据处理与人工智能系统将会进一步融合,最终形成开放智能计算架构的最佳实践。
- 多样化的计算,如流、图、机器学习经常并存于业务场景中,蚂蚁金服联合 Berkeley 大学推进的新一代计算引擎 Ray,着力于打造一个多模,融合的金融级计算引擎,帮助业务以简单的函数式编程实现多样化的分布式计算功能。
- 蚂蚁金服最新开源的 SQLFlow,抽象出端到端从数据到模型的研发过程,配合底层的引擎及自动优化,我们希望让人工智能应用像 SQL 一样简单。
以下是蚂蚁金服副CTO胡喜的分享内容全文
蚂蚁金服过去十五年,通过技术重塑了支付服务小微贷款服务。我们认为 Blockchain (区块链)、Artificial intelligence(人工智能)、Security(安全)、 IoT(物联网)和 Cloud computing(云计算),这五大 BASIC 技术仍会是金融科创新发展的基石。
但是,在 BASIC 技术中最基础的能力是计算能力,只有不断提升计算能力,才能适应未来应用场景的千变万化。对蚂蚁来说,要解决两个最关键的计算问题,一个是在线交易支付的问题,另外就是解决金融级数据智能的问题,狭义来讲就是 OLTP 和 OLAP 的问题。
金融级云原生,让交易支付更简单
讲到金融在线交易,肯定要讲到“双十一”。因为“双十一”是整个中国 IT 届技术驱动力的盛世,蚂蚁在“双十一”的发展过程当中,可以看到金融支付几乎每年都是三倍的增长,到今天,整个系统具备百万级每秒的伸缩支付能力。

背后到底怎么做的?有些技术能力就跟跳水项目的规定动作一样,一定要具备这些能力。比如怎么做分布式、微服务,消息队列的问题。具体到蚂蚁,更重要的是解决分布式事务的问题,怎么做高可用,怎么做一致性,数据不能有任何丢失,不能有任何偏差,到最后怎么能够完成金融级的分布式中间件,到现在为止,我们可以看到一点,在高可用,一致性方面我们已经做到在任何情况下的数据最终一致,保证每一笔支付扣款的资金安全。并且我们去年对整体内部的中间件进行了开源,SOFAStack 是我们这么多年沉淀在金融级的最佳实践,我们期待这些实践能够帮助到更多人,从最近开源的数据来看,有 23000 的 Star,100 多个同学来参与贡献,欢迎大家更多地去试用。

刚刚讲中间件是能够在跟数据库无关前提的情况下,能够把整个金融交易做好,这是我们基本的要求,但金融交易技术中最关键的是分布式数据库能力。2009 年,蚂蚁启动自主研发数据库 OceanBase,这是一个非常偏向于高可用,一致性分布式的数据库,通过 Paxos 算法解决内部一致性的问题,到今天为止,蚂蚁整个数据库全部跑在 OceanBase 之上。
我常常会说什么才是核心技术?有些人说,核心技术只要投入人就可以做好,其实不是这么回事,核心技术不仅仅是有人有资源,还需要时间的积累,是需要天时地利人和,还需要公司、整个业务的支持,才能发展到今天,做技术还是需要一点技术情怀,蚂蚁就是一直这样坚持下去,十年左右的时间坚持开发自己的数据库,从零开始写第一行代码,到现在为止,OceanBase 数据库集群最大处理峰值是 4200 万次 / 秒,单集群最大的节点超过 1000 台,最大存储容量超过 2PB,单表最大的行数是超过 3200 亿行,并且在少数副本故障的情况下,能够做到 RPO=0,RTO<30 秒,这个是我们对于数据库层面上所做一些努力。

此外,对于金融级系统来说,怎么保证数据不丢失,业务不停机。所以蚂蚁做了三地五中心多活的架构,在去年 9 月的杭州云栖大会上,我们现场用剪刀,把杭州机房的一台正在运行的服务器的网线剪断,整个业务没有受到任何影响,完全恢复的时间是 25 秒。
但是除了出了问题能够快速及时恢复,还不够,我们都是做软件的,我们知道软件没有银弹,蚂蚁的系统天天在变更,蚂蚁去年变更数量接近 30 万次,未来 1—2 年之内会增长到一百万次的变更,也就是说每天接近三千多次的更新,而变更是所有软件出现问题最大一个点,不变更有可能不会出问题,变更就会出问题。怎么保证系统在变更之后还能保证之前的高可用和容灾能力,这就需要技术风险的自我恢复能力。
在这方面,蚂蚁内部做了一套技术风险体系叫 TRaaS,它在高可用和资金安全风险方法能力的基础上,可以做到五分钟发现、五分钟恢复,这个是基础。另外一点则是主动的发现故障的能力,因为有时候出了问题才知道这个地方是问题了,不出问题觉得这个架构是非常完美的。所以,蚂蚁通过红蓝对抗,每天都在不断主动发现故障,这个就是技术风险的防范体系,也叫蚂蚁的免疫系统。

即便总是问自己现在的系统架构是否是一个完美的架构,我们发现还有很多地方没有做好,因为从应用研发的角度来看,它们还是需要考虑太多的东西,比如容灾,一致性,sharding 很多金融级要考虑的问题,我们期望于业务不需要考虑金融级能力相关的事情,就可以享受到金融级应用相关的能力。所以从去年开始,蚂蚁开始把相应的系统做 Mesh 化改造,之所以今天我们能提 Mesh 的概念,是因为为我们之前做了很多前置的准备,分布式中间件、数据库、容灾,技术风险等等,只有这些准备好以后,才能通过 Mesh 化把金融级的能力沉淀到基础设施,这样业务才能更简单。
未来,金融级分布式系统,最终将走向云原生化,现有的中间件能力将通过 Service Mesh 形式下沉至基础设施,安全可信的执行环境是金融级系统的底线,安全容器将成为金融行业的强需求。
从这个判断出发,蚂蚁组建了专门的安全容器技术团队,并且邀请了 Kata 安全容器技术创始人等一些顶级贡献者加入蚂蚁,一起来打造面向下一代的金融级安全容器技术。现在,托管于 OpenStack 基金会的 Kata Containers 项目,已经成为 OpenStack 基金会旗下的首个顶级开源基础设施项目项目。蚂蚁会持续关注并积极参与最前沿的安全容器技术,会先在内部场景验证这个技术,然后开放出来更好地服务整个社区。接下来,开发者可以享受到阿里集团、蚂蚁金服对 Kata 技术的改进和贡献,并将各项改进和优化贡献给 Kata 社区。
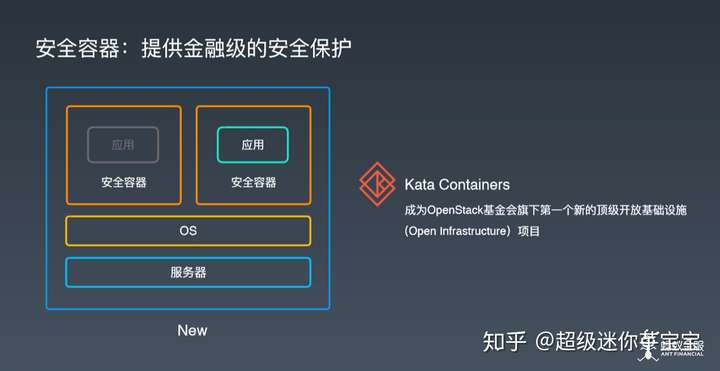
在这条金融级云原生的演进之路上,会发生端到端的变革。在可信计算方面,要从硬件到软件,都是可信的,不仅运行环境是可信的,数据也需要是加密的,这就需要对原有的操作系统做很多优化;另一方面,Mesh化也需要系统层做很多的优化。今天我们在系统层方面看到,很多系统层面的技术成熟后都在向硬件沉淀,而在应用层的很多中间件逻辑,也在逐渐向系统层沉淀,而很多系统级的工作又有通过bypass kernel来提高特定场景下的性能的趋势,这些软件技术不断发展的结果,最终支持着高效可信的金融级云原生架构,让应用层的事情做起来前所未有的简单。但在这简单的背后,酝酿的是对今天的计算体系架构的重大的变动。
总结来看,交易支付的理想架构这包括分布式中间件、分布式数据库、技术风险防控体系、安全可信的容器基础设施、以及Service Mesh。以此来保证金融业务开发非常简单,业务只需要关注自己的事情,其他都交给金融级云原生基础设施来完成。
金融级数据智能架构的最佳实践是开放智能计算架构
解决了 OLTP 的问题,我们在数字金融发展过程中还有一个非常大的问题要解决,那就是数据智能问题,背后是数据计算和 AI 的问题。
对于蚂蚁技术来说,金融级的数据智能怎么去做?我们首先回顾一下对于大数据支撑业务发展的基本要求。首先是要解决 PB 级数据量的计算问题,所以有了 MapReduce 或 RDD 的方式,对于蚂蚁来说是用的内部研发的 MaxCompute,开源的有 Hadoop、Spark 这样的技术;同时我们也对数据计算时效性开始有需求,开始需要 Streaming 计算,相应的技术有 Flink,Storm 等技术,我相信很多公司用这样的技术解决类似的问题;对于金融业务来看对图计算的需求是基本需求,比如怎么解决反的关系网络问题,怎么解决内部知识图谱的问题等等,这些都需要通过图计算来解决,蚂蚁内部一直在使用自研的 GeaBase 来解决图计算的问题,同时在 Graph 领域开源的技术也有很多,像 Neo4j 或 TigerGraph 等产品。最后业务还有交互式快速查询的需求,就有了 OLAP/MPP 技术,今天这个架构非常多,我们内部用自研的 ADS 和 Explorer 来解决问题,开源的有 Impala、Drill、Presto 这样的产品;不同的计算需求还有很多,这里就不一一列举,但是我相信大家都在用自己的方式去解决大数据计算的问题。
但是计算的多样性满足了业务需求,也带来了一些的问题。比如,不同计算类型都有不同的研发框架和语言类型,带来的研发效率问题;多种计算类型带来多样存储需求,往往需要额外的存储,带来成本问题;金融需要不同的容灾和数据治理的要求,带来架构落地复杂度问题。
所以我们希望的计算架构是开放的。依靠一套引擎打天下是完全不可能的,必须要更为开放的技术架构。
- 首先,要有一个统一的存储层,在这层去统一存储的规范和标准,建立统一的虚拟表机制,屏蔽底层的存储的多样性,保证可以支持各种计算的需求;
- 其次,对于计算引擎层,我们需要能够支持多种计算引擎,并且让这些引擎做到可插拔,并且通过 SPI 方式,实现元数据接入,容灾,安全合规的标准化问题。
- 再者,期望有一套标准化的 SQL 层,因为 SQL 是现在所有引擎的接口标准,我们也期望提供一个统一的数据访问层来解决研发界面统一的问题,而且是希望数据科学家,运营人员也能够使用。
- 最后,是提供一个一站式数据智能研发平台,来解决数据应用的高效研发和规范问题。这个事情我们做了两年,去年已经验证了这个事情已经在多个场景进行落地,大大降低了研发成本,结合资产的治理,以前需要上万行代码的数据应用,现在只需要上百行代码就可以解决了。
开放计算架构解决了计算的复杂度,研发效率,成本的问题,但还不够。每个场景都会有自己的特点,需要特性化的计算引擎。举一个花呗反的例子,这是一个很简单、很正常金融的问题,而背后需要做什么事情?因为要做实时反,是要做特征实时计算的,而特征计算的时候发现可疑账号,要往下看与这个账号有关系的账号资金处理情况,这个时候又要用到图计算的能力。对于计算的实现,大家可能会想到我首先要用到实时计算,然后如果需要图计算再转移到图计算引擎;但是这种计算的迁移转换会带来延时性问题,不能在秒级解决问题,而且切换的成本代价比较大,所以针对这种类似的场景我们设计了融合计算这样的框架。
这个框架是一个通用计算框架,底层采用的是一种动态图的元计算架构,在这个元计算架构上你既可实现 Streaming,也可以很高效地实现图计算,甚至机器学习也可以做,花呗反的图计算是需要实时更新的,所以基于动态图的元计算引擎可以很好支持这种场景。为了更好地解决多样化的计算,如流,图,机器学习经常并存于业务场景中这个问题,蚂蚁金服联合 UC Berkeley 大学推进的新一代计算引擎 Ray,着力于打造一个多模,融合的金融级计算引擎,帮助业务以简单的函数式编程实现多样化的分布式计算功能。在这样的融合计算架构下,可以秒级地完成在百亿级大图上下钻到接近 10 度邻居,远远超出普通的流式计算或者图计算引擎,扩展了业务的能力边界。

而融合计算也是开放计算架构中的一种引擎,我们可以通过智能 SQL 网关进行引擎层的动态适配。
当然我们对于 AI 来看,也可把很多机器学习框架,TensorFlow 等融合进来,而为了简化机器学习的研发,我们对智能 SQL 层进行了扩展,这个就是 SQLFlow,一种面向 AI 研发的简单的语言。
今天,机器学习工具 SQLFlow 已经正式开源。SQLFlow 抽象出端到端从数据到模型的研发过程,配合底层的引擎及自动优化,蚂蚁希望让人工智能应用像 SQL 一样简单。

金融级数据智能未来的趋势是 Big Data Base,我们需要开放式的计算架构,从统一存储规范,可插拔的引擎组件,融合计算引擎,到统一的智能 SQL,数据处理与人工智能系统将会进一步融合,最终形成开放智能计算架构的最佳实践。
BASIC College —— 蚂蚁金服人才培养机制
2009 年,UC Berkeley 大学发表了一篇论文,开启了云计算新的浪潮。事实上,这些年很多云计算相关的业务,技术都是对那篇论文的最佳实践。最近,UC Berkeley 发了这个系列另外一篇,关于云计算下一步未来的发展是什么,今天讲的金融级云原生,云原生架构都是其中的内容。而背后所有的事情则是计算机体系架构在未来的几年会有比较重大的变化。
今天为什么讲这个事情?因为在计算机体系架构进化中,人才是促使进化的关键点。
有一个事情对我有很大触动。我听别人说:Google 为了做好 TPU 的性能优化,从全公司能够紧急调集几十个做编译器的人才,而且这个还不是全部编译器人才,听说只是挑选了一些。今天,国内到底哪家公司能够拿出几十个这样的人才?我相信是很少的。而今天中国整个软件业的发展,一定是非常需要计算机体系架构方面的人才,尤其是编译器,操作系统,硬件方面的人才,软件领域每一次重大变化都会带来一次重构和抽象,这个都会需要具备这样素质的人才。
所以我觉得人才是非常非常关键的,只有找到这些人才,才能把这些事情好,才能做一些大的变化,才能对未来的不确定性做一些准备。在蚂蚁金服内部有着一个叫“BASIC College”的技术培养体系,BASIC 一方面对应着 Blockchain (区块链)、Artificial Intelligence(人工智能)、Security(安全)、 IoT(物联网)和 Cloud Computing(云计算)五大领域,另一方面代表我们始终专注于金融科技的本质——计算机基础技术能力的提升。因此,蚂蚁金服的“BASIC College”主要围绕热门或前沿的领域,做有针对性的培训,比如 AI 课程等;同时,课程还会涉及到蚂蚁历史上的重要技术方向决策。另外,我们除了有内部的讲师团,还邀请外部的专家、学者进行技术的分享与交流。我们认为,只有整个技术氛围是开放的才可能真正把技术这件事做到极致。

蚂蚁金服拥有非常大的场景,每个技术人都有足够的空间在这个平台上施展自己的抱负。我所讲到的所有技术都是背后这张图里面的这群人做的,他们开发了数据库,研发了风控系统,设计了计算架构,包括融合计算等等很多东西。其实我是这群人里面技术最弱的。

本文为云栖社区原创内容,未经允许不得转载。